

Inside Google DeepMind's Quest to Build Infinite Digital Worlds
Genie 3 co-lead Jack Parker-Holder on the journey that led to Google's latest world model

💡 This Week’s Big Ideas
🚀 Next Thursday we’re hosting a live “AI Faire” in Los Angeles, and you’re invited! Register now and meet speedrun founders building world-changing AI tech in person.
⚔️ Jon Lai argues that founders should worry less about competitors, and even that “more competition is good for you.”
💬 Robin Guo shares the most creative cold DM he’s received recently.
💰 SR004 alums at Coverd have raised $7.8mm “to make personal finance suck less.”
📣 We’re hiring a Lifecycle Marketer to lead investor-facing marketing for the a16z speedrun team! Check Doug McCracken’s post on LinkedIn for details.
💼 Ready for your next adventure? Join our talent network to get access to hundreds of open roles. If we see a fit for you, we'll intro you to relevant founders in the portfolio.


Among the most enticing frontiers in AI tech are world models—AI models that generate virtual environments with an embedded understanding of the physical world.
For those who’ve been closely watching this space, it’s been clear for some time that world models could lead to a new form of interactive media. Leading startups like Dr. Fei-Fei Li’s World Labs1 are teaching models to simulate reality more richly than would be possible via traditional methods like game engines of 3D animation software. And the tech is evolving fast.
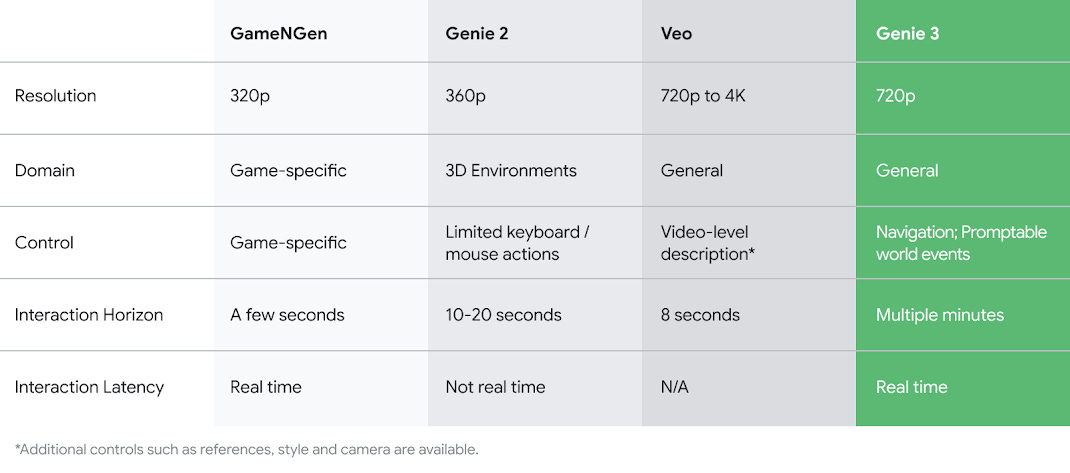
Last week, the team at Google DeepMind showed just how quickly this branch of the AI tech tree is growing with its reveal of Genie 3, a tool that turns text prompts into “dynamic worlds that you can navigate in real time at 24 frames per second.” And critically, the Genie 3 teaser demonstrated meaningful progress on challenging features like persistence of in-world objects.
So what are world models going to be used for? Entertainment seems like one likely route, but in its official announcement of the model the DeepMind team also made the case that world models are critical for accelerating other areas of AI development.
“World models are also a key stepping stone on the path to AGI,” Genie 3 co-leads Jack Parker-Holder and Shlomi Fruchter wrote, “since they make it possible to train AI agents in an unlimited curriculum of rich simulation environments.”
We were curious about the journey that led to the development of this latest model, so we reached out to Genie 3 co-lead Jack Parker-Holder for a quick Q&A.
From Game to Genie: A Q&A with Google DeepMind
a16z speedrun: We’d love to hear the story of the Genie series of models, with a focus on the most important advances that led to Genie 3. Basically, how’d we get here?
Jack Parker-Holder: In 2022 we were working on training general reinforcement learning agents using simulated environments. The challenge was, we didn’t have sufficiently rich and diverse environments to get the level of generality required for AGI. Instead, we had the crazy idea to train a world model that could generate environments—a “foundation” world model so to speak. We were inspired by progress in LLMs and text-to-image models and thought that video would be next, and then interactive video (i.e. world models) would follow.
The big challenge was: Where do actions come from if we want to leverage large video datasets that do not have action labels? With Genie 1, we designed a solution that made use of latent actions, which were learned unsupervised from the data. This essentially meant we could use unsupervised learning to discover a general, universal action space across all of the training data, and we found that they had semantic meaning. In the paper we trained two separate models, one with platform game data, the other with robotics data. In both cases, we could create new worlds and interact with the model. Genie 1 won a “best paper” award at ICML 2024 (only 1 year ago).
What was interesting with Genie 1 was that although we designed the model to be useful for agents, it was also fun to play and could already enable new forms of creativity. This inspired several external works to create game-like models, and the space took off.
As we mentioned before, when Genie 1 was being developed, video models were still in their infancy. However, by the time it came out, there had been huge progress in the space and latent diffusion models were shown to scale effectively. We then decided to push the Genie idea to a larger dataset combining both 2D and 3D environments— which produced the Genie 2 model.
Above: A clip provided by the DeepMind team shows how Genie 3 can generate a consistent and interactive world over a longer horizon compared to Genie 2.
JPH (continued): It seems obvious now in hindsight, but Genie 2 was a bet that autoregressive generation could scale. We had the first signs of memory and consistency, while we saw emergent knowledge of physical properties of worlds. Genie 2 only supported image prompting but could simulate smoke, mirrors, gravity and water, all from an image. We also saw for the first time that we could use the Genie 2 worlds to test agent capabilities, and we found that the SIMA agent (an agent trained to achieve language goals in 3D environments) could solve simple tasks in game-like worlds.
However, Genie 2 had limitations, it was not real time, and it was not yet at the quality of existing video models and the generated worlds typically degraded after 20 seconds. This is when we joined forces with Shlomi, who had not only been co-leading Veo 2, at the time the world’s best video model, but had also been one of the drivers of GameNGen (aka “the doom paper”) which really showed the impact of real time generation. We thus decided to work together to push the frontier in every dimension. We formed an incredible team, set ambitious goals, and got to work.
Rapid Fire Q&A w/ DeepMind’s Jack Parker-Holder
SR: In the announcement, your team highlighted many possibilities for real-world applications: entertainment, education, rich simulations for training AI agents. Which of these is most likely to hit scale first?
JPH: That’s a great question. At this point we have had amazing feedback from all of the areas you described and we are excited to see where each of them goes. This is a new type of foundation model and the first of its kind, so it is hard to predict exactly. Just like when LLMs first emerged on the scene, we didn’t know they’d be used for vibe coding or many of the other amazing applications we see today.
SR: What are some of the current limitations you’re working on addressing?
JPH: It is definitely the case that we have more work to do to improve the model, which is exciting! We see that the more dynamic scenes tend to work less well. It is not so much a degradation, but the motion tends to reduce. This is something we have plans to fix already in future.
SR: What would it take, technically-speaking, to scale this beyond a research preview into a broadly-accessible product?
JPH: There are many considerations with new technologies like this. Given the scope of a model like Genie 3, there are many things we need to work on before we could release more widely, and we are working to make this possible. Most importantly, we want to be sure that we develop new models and products in a responsible way.
Thanks to the DeepMind team for taking on our questions!
What would you like to know about world models? Let us know in the comments.

More from behind the scenes at a16z speedrun
George Strompolos changed entertainment forever when he co-created the YouTube Partnership Program. Now, as cofounder and CEO of Promise he’s aiming to build a next-generation, AI-native studio that aims to enable “a new type of storyteller, a new type of filmmaker.”
In a fireside chat live with a16z speedrun founders, Strompolos explained why he’s taking a collaborative approach—not “waving the pirate flag”—when approaching the film industry with the pitch for Promise.
For more weekly dives into the cutting edge of tech, entertainment, and AI, subscribe below.
You are receiving this newsletter since you opted in earlier; if you would like to opt out of future newsletters, you can unsubscribe immediately.
This newsletter is provided for informational purposes only, and should not be relied upon as legal, business, investment, or tax advice. You should consult your own advisers as to those matters. This newsletter may link to other websites and certain information contained herein has been obtained from third-party sources. While taken from sources believed to be reliable, a16z has not independently verified such information and makes no representations about the enduring accuracy of the information or its appropriateness for a given situation.
References to any companies, securities, or digital assets are for illustrative purposes only and do not constitute an investment recommendation or offer to provide investment advisory services. Any references to companies are for illustrative purposes only; please see a16z.com/investments. Furthermore, this content is not directed at nor intended for use by any investors or prospective investors, and may not under any circumstances be relied upon when making a decision to invest in any fund managed by a16z. (An offering to invest in an a16z fund will be made only by the private placement memorandum, subscription agreement, and other relevant documentation of any such fund which should be read in their entirety.) Past performance is not indicative of future results.
Charts and graphs provided within are for informational purposes solely and should not be relied upon when making any investment decision. Content in this newsletter speaks only as of the date indicated. Any projections, estimates, forecasts, targets, prospects and/or opinions expressed in these materials are subject to change without notice and may differ or be contrary to opinions expressed by others. Please see a16z.com/disclosures for additional important details.
World Labs is an a16z portfolio company: https://a16z.com/announcement/investing-in-world-labs/
World-models are *the* crucial missing piece for AGI. Not just physics or graphics, but accurate models of economics and interpersonal relations are essential for AI to have any concepts of facts, goals, interests or plans, as well as for AI to have any way to evaluate the reliability of inputs, significance of events (including counterfactuals), and quality of outputs. Further, to align AI with each user (the only possible real alignment, alignment with abstract people is undefinable), there have to be not only common base world-models but forked versions for each group, further customized for each user and even task.
The problem is getting the AI to use the world-model (or tools in general) consistently. It may well require retraining from scratch, though it may be possible to largely replace fine-tuning and even some RL with direct editing of model weights using representation-engineering and related "mindspace navigation" techniques.
Thank you for sharing such valuable content. With this content, I learned that Shlomi is part of the paper: GameNGen. Now I'm learning more about his approaches for real-time world generation.